
“你可以拥有数据而没有信息,但没有数据就无法获得信息。” —
根据最新数据,全球互联网已经有超过个网站,每天还在新增大约200万个网页内容。在这片数据海洋里,隐藏着无数有价值的信息,能为决策提供强有力的支持。但问题是,其中大约的数据都是非结构化的,只有经过进一步处理才能真正发挥作用。这正是网页爬虫工具大显身手的时候,对于想要高效获取网络数据的人来说,网页爬虫工具已经成为不可或缺的利器。
如果你刚开始接触网页爬虫,像和这些词可能会让人有点头大。但在AI时代,这些技术门槛已经大大降低。现在的ai网页爬虫工具不需要你有编程基础,也能轻松上手,帮你快速采集和处理数据,完全不用写代码。
2025年最值得推荐的网页爬虫工具和软件
- :追求极致易用和高效结果的AI网页爬虫首选
- :实时监控和批量数据采集的好帮手
- :无代码自动化,强大应用集成能力
- :适合有经验用户的可视化网页爬虫
- :强大无代码爬虫,轻松应对IP封锁和反爬机制
- :面向开发者的AI数据提取API和知识图谱
体验AI网页爬虫的强大功能
动手试试看!你可以边看边操作,体验整个自动化流程。
网页爬虫是怎么工作的?
网页爬虫的核心就是自动帮你从网站上提取需要的数据。你只要设定好需求,工具就能把网页上的文本、图片等内容整理成表格。无论是电商价格监控、市场调研,还是日常整理Excel或Google Sheets,都非常实用。
 这张图就是用Thunderbit的ai网页爬虫做出来的。
这张图就是用Thunderbit的ai网页爬虫做出来的。
网页数据采集的方法有很多。最简单的当然是手动复制粘贴,但面对大量数据时,这种方式效率极低。所以,大多数人会选择三种主流方式:传统网页爬虫、ai网页爬虫或者自定义代码。
传统网页爬虫是通过设定规则,按照网页结构抓取指定内容。比如,你可以让它提取特定HTML标签下的商品名称或价格。这类工具适合结构比较稳定的网站,但只要页面布局一变,就得重新调整爬虫设置。
 传统爬虫的学习和配置过程比较繁琐,经常需要多次点击和调试。
传统爬虫的学习和配置过程比较繁琐,经常需要多次点击和调试。
ai网页爬虫就智能多了:它有点像让ChatGPT“读懂”整个网页,然后根据你的需求提取内容。ai网页爬虫不仅能采集数据,还能同步完成翻译、摘要等操作。借助自然语言处理技术,ai网页爬虫能自动适应网页结构的变化,比如网站版块顺序调整时,ai网页爬虫通常不用你手动改规则,依然能正常工作。对于结构复杂或经常变动的网站,ai网页爬虫绝对是更省心的选择。
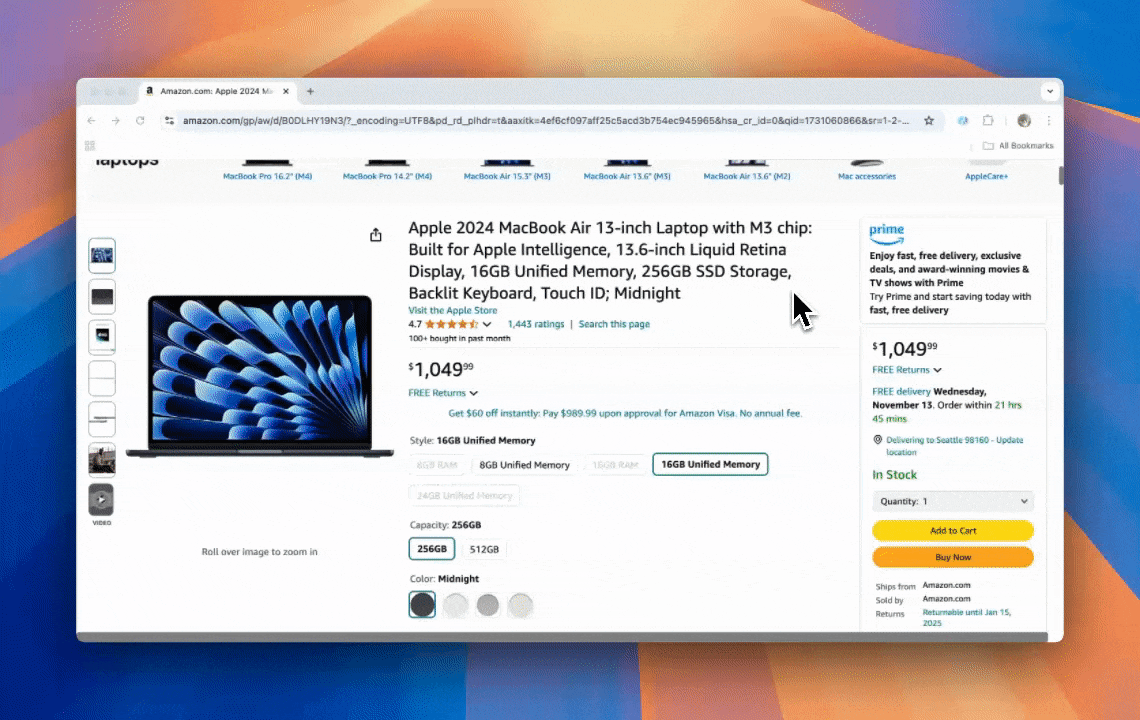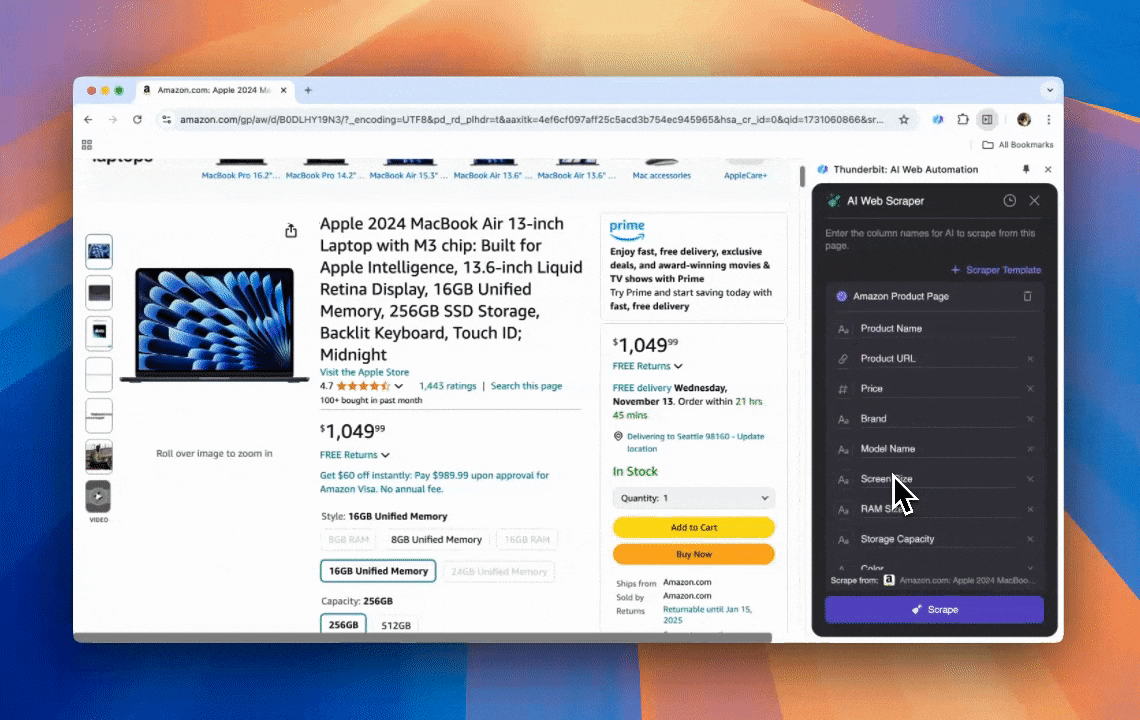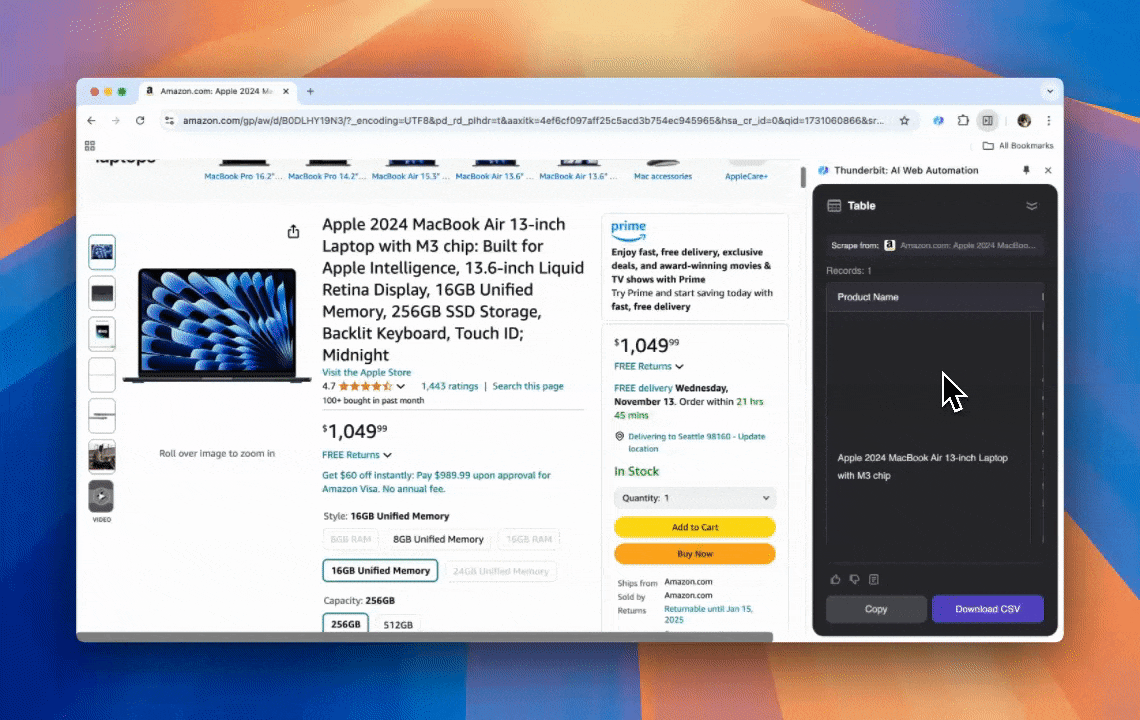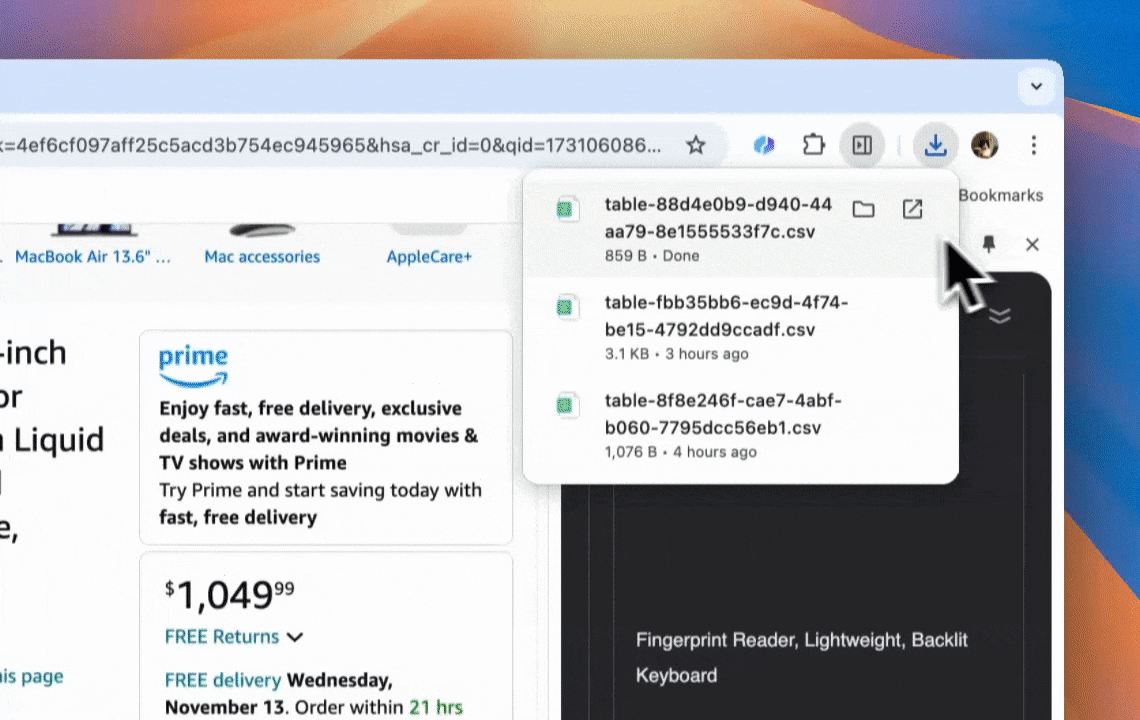
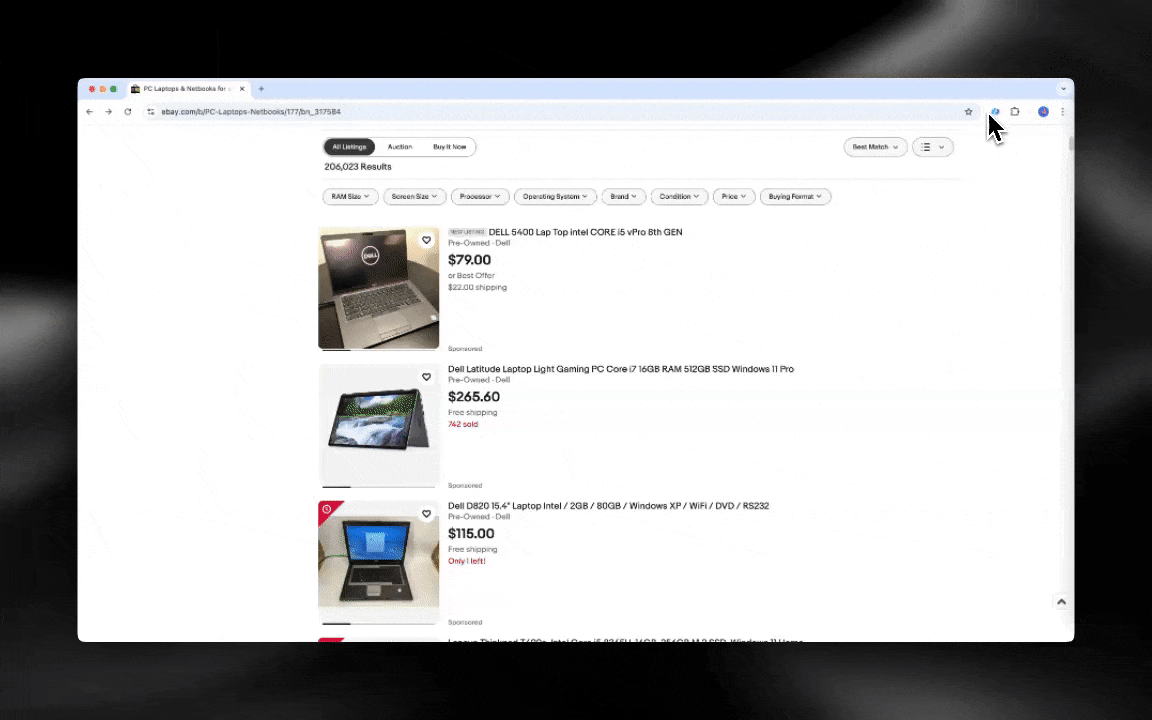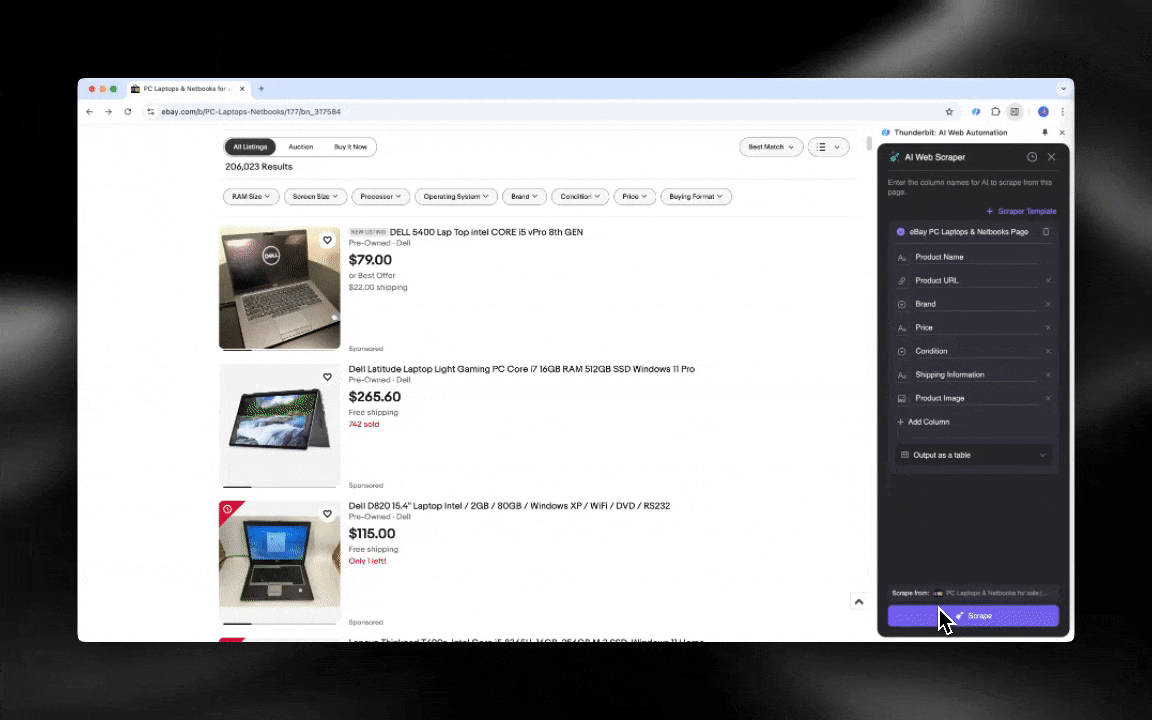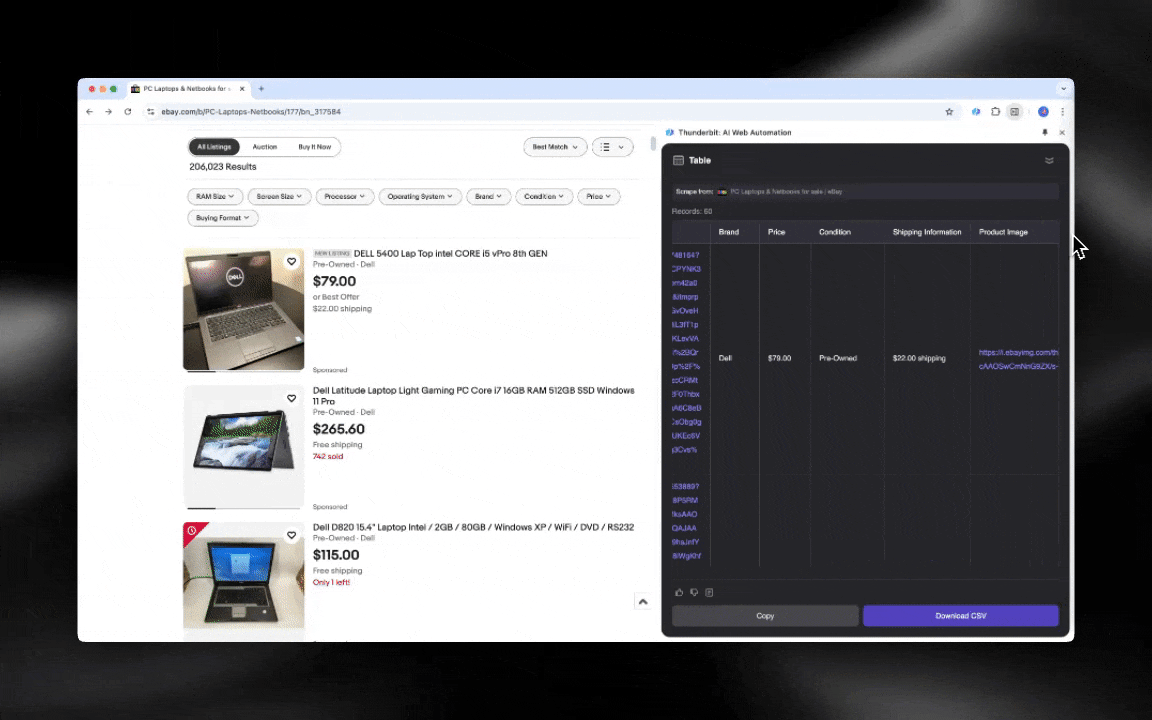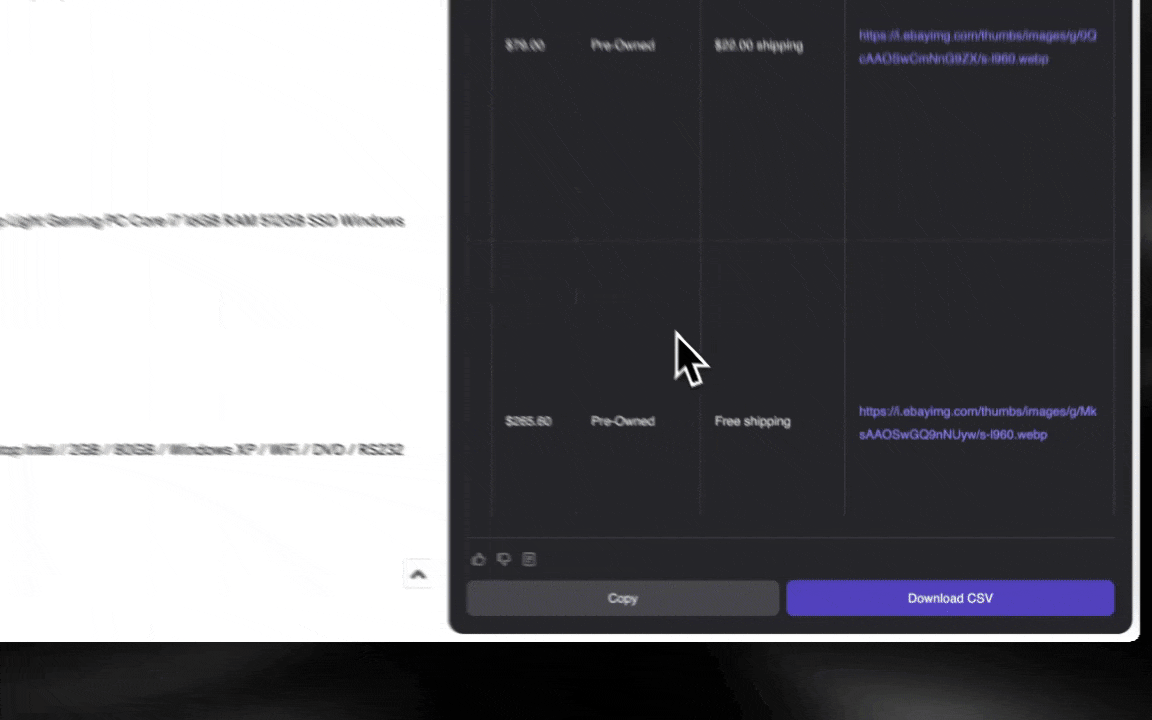 ai网页爬虫上手极快,只需几步就能拿到详细数据!
ai网页爬虫上手极快,只需几步就能拿到详细数据!
到底该选哪种? 这得看你的具体需求。如果你熟悉代码,且需要大规模采集热门网站的数据,传统爬虫效率更高。但如果你是新手,或者希望工具能自动适应网页变化,ai网页爬虫会更合适。下面这张表格可以帮你快速判断:
| 场景 | 最佳选择 |
|---|---|
| 轻量级采集,如目录页、购物网站或任何带列表的网站 | ai网页爬虫 |
| 页面数据少于200行,传统爬虫配置耗时太长 | ai网页爬虫 |
| 需要特定格式的数据以便上传到其他平台(如采集联系人信息上传到HubSpot) | ai网页爬虫 |
| 大规模采集热门网站,如成千上万条亚马逊商品或Zillow房源 | 传统网页爬虫 |
网页爬虫工具和软件一览
| 工具 | 价格 | 核心功能 | 优点 | 缺点 |
|---|---|---|---|---|
| Thunderbit | $9/月起,提供免费版 | ai网页爬虫,自动识别与格式化数据,支持多种格式,一键导出,界面友好 | 无需代码,AI辅助,支持与Google Sheets等应用集成 | 大规模采集速度较慢,高级功能需付费 |
| Browse AI | $48.75/月起,提供免费版 | 无代码界面,实时监控,批量采集,支持工作流集成 | 易用,支持Google Sheets和Zapier集成 | 复杂页面需额外配置,批量采集易超时 |
| Bardeen AI | $60/月起,提供免费版 | 无代码自动化,集成130+应用,MagicBox一键生成工作流 | 集成丰富,适合企业扩展 | 新手上手有难度,初期配置耗时 |
| Web Scraper | 本地免费,云端$50/月 | 可视化任务创建,支持动态网站(AJAX/JS),云端采集 | 动态网站表现好 | 需一定技术基础,复杂场景需反复测试 |
| Octoparse | $119/月起,提供免费版 | 无代码采集,自动识别页面元素,云端定时采集,丰富模板库 | 动态网站适应性强,能应对反爬限制 | 复杂网站需学习配置 |
| Diffbot | $299/月起 | 数据提取API,无需规则,NLP处理非结构化文本,知识图谱 | AI提取能力强,API集成丰富,支持大规模采集 | 非技术用户上手有难度,需编程调用API |
AI时代的最佳网页爬虫
Thunderbit是一款强大又好用的AI网页自动化工具,就算你完全不会编程,也能轻松采集和整理网页数据。通过,Thunderbit的ai网页爬虫让数据采集变得超级简单——不用手动操作网页元素,也不用为不同页面反复配置爬虫。
核心功能
- AI智能识别:Thunderbit的ai网页爬虫能自动检测并格式化网页数据,无需手动设置CSS选择器。
- 极简操作体验:只需点击“AI建议列”,再点“抓取”就能完成数据采集。
- 多格式数据支持:能采集网址、图片等多种内容,并以多种格式展示。
- 自动化数据处理:AI能实时对数据进行重组、摘要、分类、翻译等处理。
- 一键导出数据:支持一键导出到Google Sheets、Airtable、Notion等,数据管理更高效。
- 友好界面:操作界面直观,适合各种用户。
价格
Thunderbit有多种套餐,基础版每月$9(含5,000积分),最高可选$199/月(24万积分)。年付套餐还能一次性获得全年积分。
优点:
- 强大的AI支持,大大简化数据采集和处理流程。
- 无需编程,人人都能用。
- 轻量级采集(比如目录、购物网站)表现特别好。
- 高度集成,支持一键导出到主流应用。
缺点:
- 大规模数据采集时,为保证准确性可能需要更长时间。
- 部分高级功能需要付费解锁。
想了解更多? 可以,或者去学习如何轻松采集网页数据。
数据监控和批量采集首选网页爬虫
Browse AI
Browse AI是一款无需编程的网页数据采集工具,帮你轻松提取和监控网页数据。虽然有部分AI功能,但整体智能化程度不如全功能ai网页爬虫。不过,它的易用性让新手也能很快上手。
核心功能
- 无代码界面:通过简单点击就能自定义采集流程。
- 实时监控:用机器人自动追踪网页变动,第一时间推送最新数据。
- 批量采集:一次能处理多达5万条数据。
- 工作流集成:支持多个机器人协作,满足复杂数据处理需求。
价格
基础套餐$48.75/月(含2,000积分),免费版每月可试用50积分。
优点:
- 支持与Google Sheets、Zapier等工具集成。
- 预设机器人简化常见采集任务。
缺点:
- 复杂页面需要额外配置。
- 批量采集速度不稳定,可能会超时。
工作流自动化集成首选网页爬虫
Bardeen AI
Bardeen AI是一款无代码自动化工具,通过连接多种应用,帮你高效整合工作流。虽然有AI自动化能力,但在网页数据采集的灵活性上不如专用ai网页爬虫。
核心功能
- 无代码自动化:通过点击就能搭建自动化流程。
- MagicBox:用自然语言描述任务,Bardeen AI自动生成工作流。
- 丰富集成:支持130+应用,包括Google Sheets、Slack、LinkedIn等。
价格
基础套餐$60/月(含1,500积分,约1,500行数据),免费版每月可试用100积分。
优点:
- 集成丰富,满足多样化业务需求。
- 灵活可扩展,适合各种企业。
缺点:
- 新用户需要一定学习时间。
- 初次配置比较耗时。
适合有经验用户的可视化网页爬虫
Web Scraper
没错,这款工具就叫“Web Scraper”。它是一款流行的Chrome和Firefox浏览器扩展,支持可视化创建采集任务,无需编程。但要完全掌握用法,建议先看上面的教程。如果你想让采集更轻松,推荐直接用ai网页爬虫。
核心功能
- 可视化操作:通过点击网页元素设置采集任务。
- 动态网站支持:能处理AJAX和JavaScript动态内容。
- 云端采集:通过Web Scraper Cloud定时执行采集任务。
价格
本地使用免费,云端功能$50/月起。
优点:
- 动态网站采集表现很棒。
- 本地使用完全免费。
缺点:
- 最佳配置需要一定技术基础。
- 页面变动时需要反复测试。
规避IP封锁和反爬机制的网页爬虫
Octoparse
Octoparse是一款功能全面、适合技术型用户的大型数据采集软件。它不依赖本地浏览器,而是通过云服务器进行数据采集,所以能有效规避IP封锁和部分网站的反爬机制,非常适合大规模数据需求。
核心功能
- 无代码操作:不用编程就能创建采集任务,适合不同技术水平的用户。
- 智能自动识别:自动检测页面数据元素,快速完成采集配置。
- 云端采集:支持7x24小时云端定时采集,灵活获取数据。
- 丰富模板库:内置数百个热门网站采集模板,无需复杂配置就能快速采集。
价格
基础套餐$119/月(含100个任务),免费版每月可试用10个任务。
优点:
- 动态网站采集能力强,适应性高。
- 能有效应对反爬限制和动态内容。
缺点:
- 复杂网站结构需要花时间配置。
- 新用户需要学习使用技巧。
高级AI数据提取API首选网页爬虫
Diffbot
Diffbot是一款面向开发者的高级网页数据提取工具,利用AI把非结构化网页内容转化为结构化数据。它强大的API和知识图谱,适用于多行业、多场景的数据采集、分析和管理。
核心功能
- 数据提取API:不用设定规则,只要提供网址就能自动提取数据。
- 自然语言处理API:从非结构化文本中提取实体、关系和情感,助力构建专属知识图谱。
- 知识图谱:拥有全球最大之一的知识图谱,涵盖人物、组织等丰富实体信息。
价格
基础套餐$299/月(含25万积分,约等于25万次API网页提取)。
优点:
- 无需规则,AI自动提取,适应性极强。
- API集成丰富,方便和现有系统对接。
- 支持大规模数据采集,适合企业级应用。
缺点:
- 非技术用户需要一定学习成本。
- 需要编写程序调用API。
网页爬虫能做什么?
如果你是新手,下面这些常见应用场景可以帮你快速入门。很多人用爬虫采集亚马逊商品信息、Zillow房产数据,或者从Google地图获取企业信息。当然,这只是冰山一角——借助Thunderbit ,你几乎可以从任何网站采集所需数据,大大提升日常工作效率。不管是做市场调研、价格监控,还是搭建数据库,网页爬虫都能让互联网数据为你所用。
常见问题解答
-
网页爬虫合法吗?
网页爬虫通常是合法的,但要遵守目标网站的服务条款和相关数据政策。建议采集前仔细阅读并遵守相关规定。
-
使用网页爬虫工具需要编程基础吗?
本文推荐的大多数工具都不需要编程,但像Octoparse、Web Scraper等工具,如果懂点网页结构和编程思维会更容易上手。
-
有免费的网页爬虫工具吗?
有,比如BeautifulSoup、Scrapy、Web Scraper等都有免费版本,部分工具也提供功能有限的免费套餐。
-
网页爬虫常见难题有哪些?
主要难点包括动态内容处理、验证码、IP封锁和复杂HTML结构。借助高级工具和技巧可以有效应对。
延伸阅读:
-
用AI轻松高效办公。