Thunderbit AI 기반 Wikipedia 웹 스크래퍼는 Wikipedia 항목과 검색 결과 페이지에서 구조화된 데이터를 손쉽게 추출할 수 있도록 설계된 강력한 도구입니다. 을 활용하면 비정형 Wikipedia 콘텐츠를 체계적인 데이터셋으로 빠르게 변환할 수 있습니다. 연구자, 학생, 데이터 분석가 등 누구나 세계 최대 온라인 백과사전에서 정보를 쉽고 빠르게 수집할 수 있습니다.

📖 Wikipedia 웹 스크래퍼로 어떤 데이터를 추출할 수 있나요?
1. Wikipedia 항목 데이터 추출
Wikipedia 웹 스크래퍼를 사용하면 Wikipedia 항목에서 섹션 제목, URL, 요약, 이미지, 참고문헌 등 다양한 정보를 체계적으로 추출할 수 있습니다. 연구나 기록 보관, 분석이 필요한 전문가에게 매우 유용합니다.
사용 방법:
- 을 설치하고 계정을 등록하세요.
- 로 이동합니다.
- AI 컬럼 추천을 클릭하면 섹션 제목, 요약 등 추천 컬럼명이 자동으로 생성됩니다.
- 스크랩 버튼을 눌러 데이터를 추출하고, 구조화된 파일로 다운로드하세요.

컬럼 예시
| 컬럼 | 설명 |
|---|---|
| 📚 섹션 제목 | Wikipedia 항목 내 각 섹션의 제목 |
| 🌐 섹션 URL | 해당 섹션으로 바로 이동하는 링크 |
| 📝 내용 요약 | 각 섹션의 주요 내용 요약 |
| 🖼️ 미디어/이미지 | 섹션에 포함된 이미지 또는 미디어 링크 |
| 📖 참고문헌 | 해당 섹션에서 인용된 참고문헌 목록 |
2. Wikipedia 검색 결과 페이지 데이터 추출
Wikipedia 웹 스크래퍼는 검색 결과 페이지에서도 데이터를 추출할 수 있어, 여러 주제에 대한 정보를 한 번에 수집할 수 있습니다. 트렌드 분석이나 관련 주제 데이터 수집이 필요한 연구자, 콘텐츠 제작자에게 적합합니다.
사용 방법:
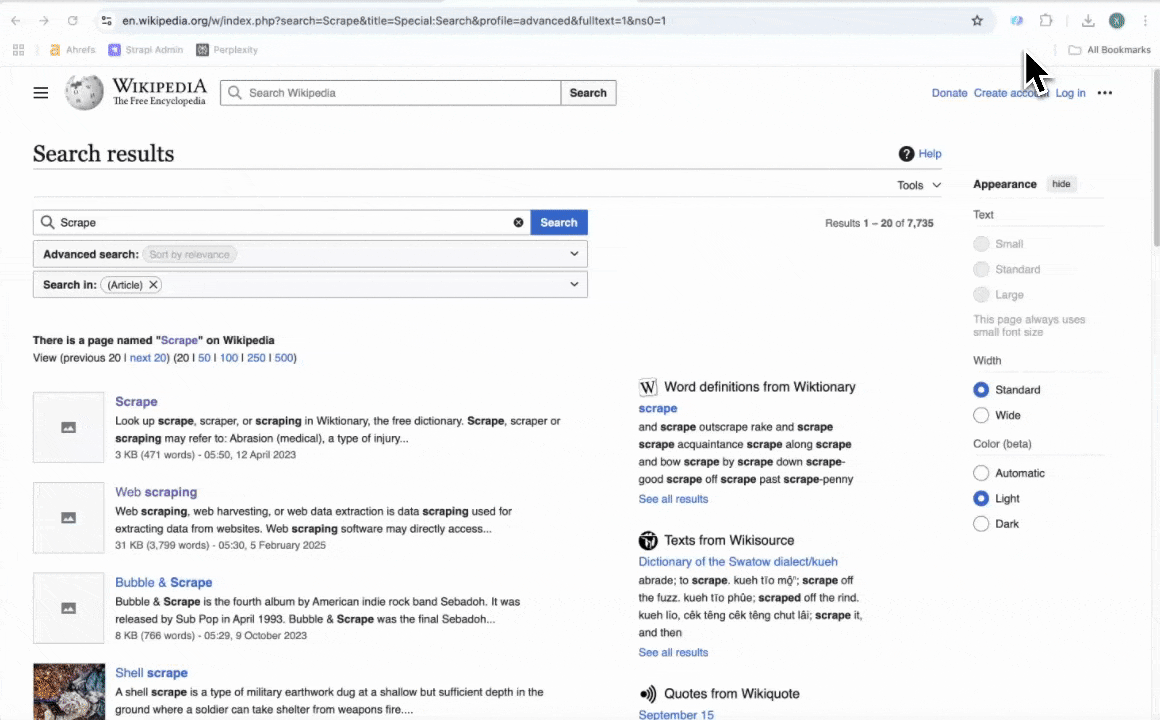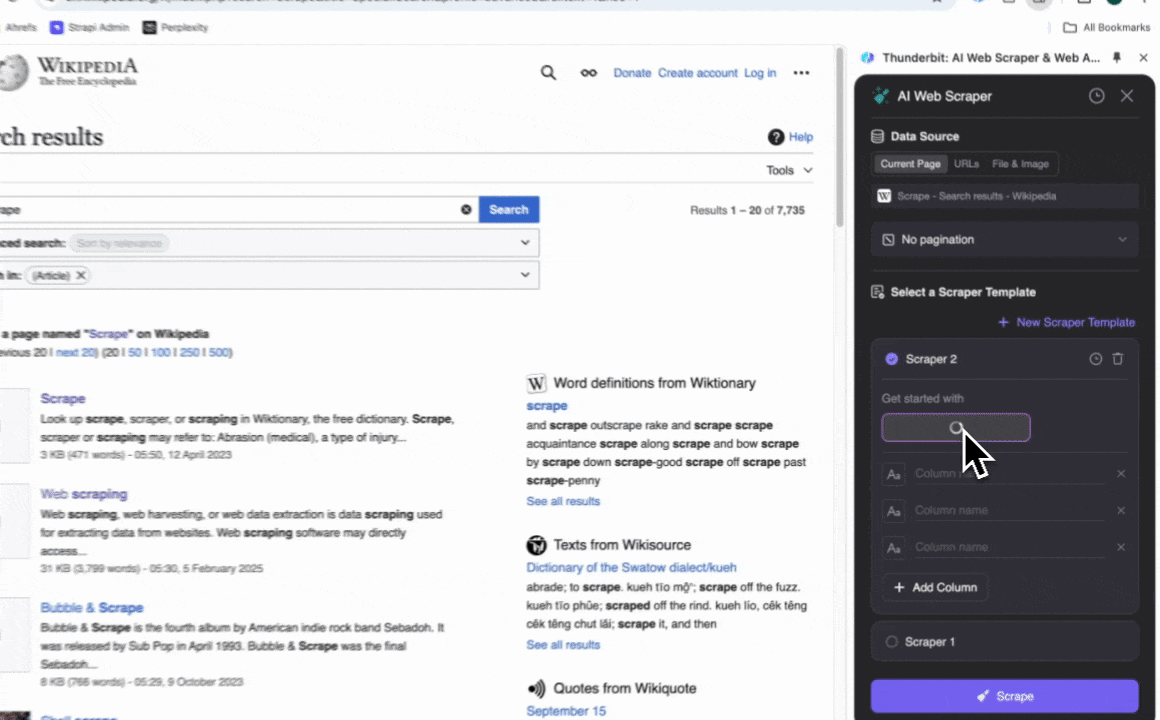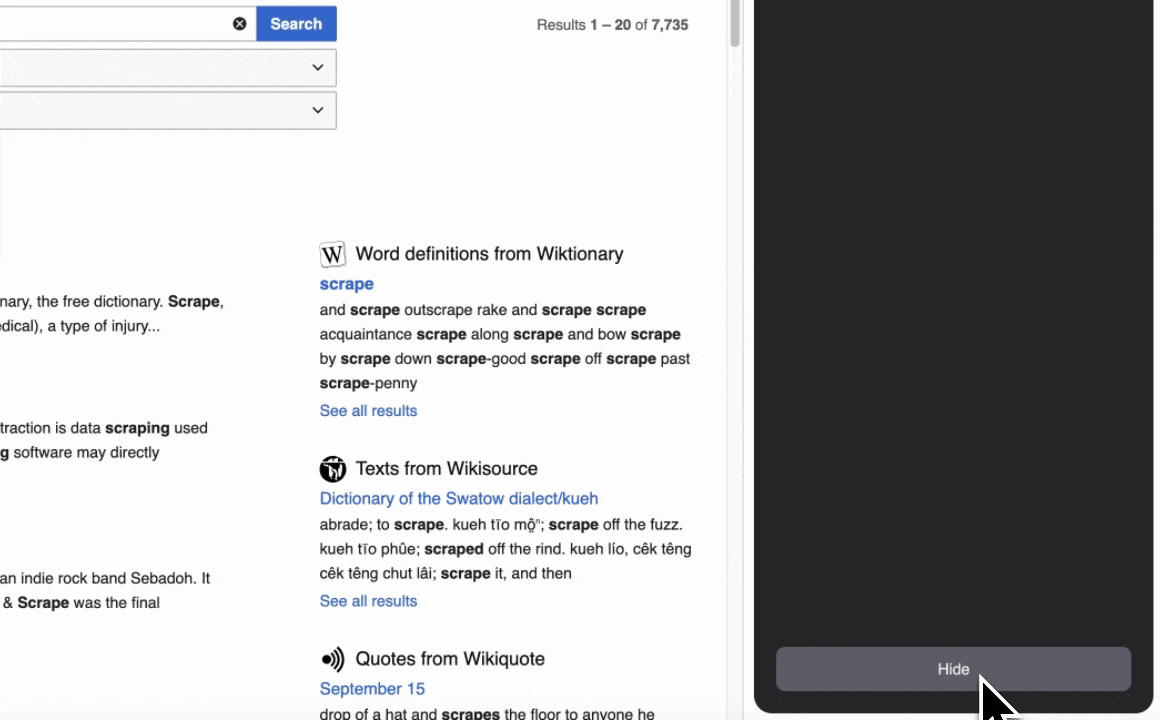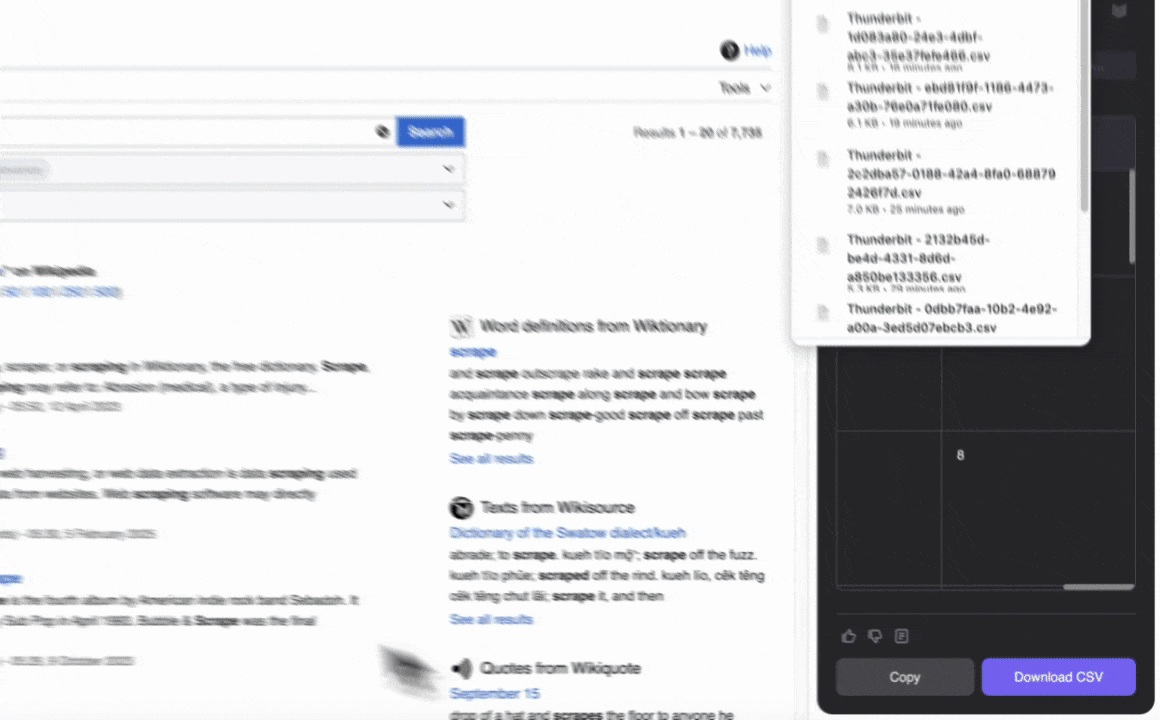
- 을 설치하고 계정을 등록하세요.
- 로 이동합니다.
- AI 컬럼 추천을 클릭하면 결과 제목, URL 등 추천 컬럼명이 자동으로 생성됩니다.
- 스크랩 버튼을 눌러 데이터를 추출하고, 구조화된 파일로 다운로드하세요.
컬럼 예시
| 컬럼 | 설명 |
|---|---|
| 📝 결과 제목 | 검색 결과의 제목 |
| 🌐 결과 URL | 해당 검색 결과로 바로 이동하는 링크 |
| 🖋️ 결과 설명 | 검색 결과의 간단한 설명 |
| 📅 최종 수정일 | 해당 페이지가 마지막으로 수정된 날짜 |
| 📏 결과 분량(단어 수) | 검색 결과 페이지의 단어 수 |
🤔 Wikipedia 웹 스크래퍼를 사용해야 하는 이유
Wikipedia 데이터를 추출하면 다양한 전문가들이 시간과 노력을 절약할 수 있습니다:
- 연구자: 학술 연구나 시장 조사에 필요한 데이터를 빠르게 수집 및 정리
- 학생: 과제나 프로젝트에 필요한 요약 및 참고문헌 추출
- 콘텐츠 제작자: 트렌드 분석 및 기사, 영상 제작에 필요한 정보 수집
- 데이터 분석가: 분석 및 시각화를 위한 구조화된 데이터 확보
Wikipedia 웹 스크래퍼를 활용하면 복잡한 복사/붙여넣기 작업 없이 데이터 분석에 집중할 수 있습니다.
🛠️ Wikipedia 웹 스크래퍼 크롬 확장 프로그램 사용법
- Thunderbit 크롬 확장 프로그램 설치: 에서 확장 프로그램을 설치하고 계정을 등록하세요.
- Wikipedia 페이지로 이동: 추출하고 싶은 Wikipedia 항목 또는 검색 결과 페이지로 이동합니다.
- AI 기반 스크래퍼 활성화: AI 컬럼 추천을 클릭해 컬럼명을 자동 생성하거나, 원하는 대로 컬럼을 직접 설정할 수 있습니다.
- 스크래퍼 실행: 스크랩 버튼을 눌러 데이터를 추출하고, 구조화된 파일로 다운로드하세요.
💰 Thunderbit Wikipedia 웹 스크래퍼 요금 안내
Thunderbit는 1 크레딧 = 1개 추출 행 기준의 크레딧 방식으로 운영됩니다. 무료로 체험할 수 있으며, 다양한 요금제가 있어 사용량에 따라 유연하게 선택할 수 있습니다.
요금제:
| 구분 | 월 요금 | 연 요금(월 기준) | 연 총액 | 월별 크레딧 | 연간 크레딧 |
|---|---|---|---|---|---|
| 무료 | 무료 | 무료 | 무료 | 6페이지 | 해당 없음 |
| 스타터 | $15 | $9 | $108 | 500 | 5,000 |
| 프로 1 | $38 | $16.5 | $199 | 3,000 | 30,000 |
| 프로 2 | $75 | $33.8 | $406 | 6,000 | 60,000 |
| 프로 3 | $125 | $68.4 | $821 | 10,000 | 120,000 |
| 프로 4 | $249 | $137.5 | $1,650 | 20,000 | 240,000 |
무료 제공 기능:
- 무료 요금제: 월 6페이지 추출 가능
- 무료 체험: 10페이지까지 무료로 사용해볼 수 있어, 기능을 충분히 체험할 수 있습니다.
❓ 자주 묻는 질문(FAQ)
-
AI 기반 Wikipedia 웹 스크래퍼란 무엇인가요?
AI 기반 Wikipedia 웹 스크래퍼는 Wikipedia 항목 및 검색 결과 페이지에서 구조화된 데이터를 추출할 수 있도록 설계된 전문 도구입니다. Thunderbit의 AI 기반 크롬 확장 프로그램을 활용해 비전문가도 손쉽게 정보를 수집할 수 있습니다.
-
Thunderbit란 무엇인가요?
Thunderbit는 인공지능을 활용해 웹 스크래핑, 데이터 추출, 자동화 작업을 간편하게 만들어주는 크롬 확장 프로그램입니다. 웹사이트에서 데이터 추출, 폼 자동 입력, 콘텐츠 요약 등 다양한 기능을 제공해 여러 분야의 전문가에게 필수적인 도구입니다.
-
무료 체험으로 몇 개의 Wikipedia 페이지를 추출할 수 있나요?
Thunderbit 무료 체험을 통해 최대 10개의 Wikipedia 페이지를 무료로 추출할 수 있습니다. 이를 통해 기능을 충분히 경험한 후 유료 플랜으로 업그레이드할지 결정할 수 있습니다.
-
추출할 컬럼과 데이터 필드를 직접 설정할 수 있나요?
네, Thunderbit는 원하는 데이터 필드를 직접 지정할 수 있는 강력한 커스터마이징 기능을 제공합니다. 섹션 제목, URL, 요약, 참고문헌 등 필요한 정보를 자유롭게 선택해 추출할 수 있습니다.
-
스크래퍼는 얼마나 자주 실행할 수 있나요?
실행 빈도는 가입한 요금제와 보유 크레딧에 따라 다릅니다. 상위 요금제일수록 더 많은 크레딧이 제공되어 대량 또는 빈번한 데이터 추출이 가능합니다.
-
크레딧이 모두 소진되면 어떻게 하나요?
크레딧이 부족할 경우, 필요에 따라 추가 크레딧을 구매하거나 상위 요금제로 업그레이드할 수 있습니다. 언제든지 기능을 계속 이용할 수 있습니다.
-
Wikipedia 데이터 추출이 합법적인가요?
Wikipedia의 공개 데이터를 추출하는 것은 일반적으로 허용되지만, 관련 법률과 Wikipedia의 이용 약관을 준수해야 합니다. 데이터를 책임감 있게 활용하고, 관련 규정을 반드시 확인하세요.
-
Wikipedia에서 이미지나 미디어도 추출할 수 있나요?
네, Wikipedia 웹 스크래퍼는 항목 내 포함된 이미지 및 미디어 링크도 함께 추출할 수 있습니다. 시각 자료가 필요한 연구자나 콘텐츠 제작자에게 특히 유용합니다.
📚 더 알아보기
Thunderbit의 다양한 기능이 궁금하다면 또는 에서 자세한 가이드와 팁을 확인해보세요.