

Thunderbit AI搭載Wikipediaスクレイパーは、Wikipediaのエントリーや検索結果ページから構造化データを簡単に抽出できる強力なツールです。を使えば、Wikipediaの非構造化コンテンツを整理されたデータセットへと変換できます。研究者や学生、データアナリストなど、幅広い方が世界最大級のオンライン百科事典から情報を効率よく収集できるようになります。

📖 Wikipediaスクレイパーで取得できるデータ
1. Wikipediaエントリーの抽出
Wikipediaスクレイパーを使えば、任意のWikipediaエントリーからセクションタイトル、URL、要約、画像、参考文献などの詳細情報を抽出できます。研究やアーカイブ、分析用途に最適です。
手順:
- をインストールし、アカウント登録を行います。
- にアクセスします。
- AIカラム提案をクリックすると、「セクションタイトル」「要約」などのカラム名が自動で提案されます。
- スクレイプをクリックしてデータを抽出し、構造化フォーマットでダウンロードします。

カラム例
| カラム | 説明 |
|---|---|
| 📚 セクションタイトル | Wikipediaエントリー内の各セクションのタイトル |
| 🌐 セクションURL | ページ内の該当セクションへの直接リンク |
| 📝 要約 | 各セクションの内容を簡潔にまとめたもの |
| 🖼️ 画像/メディア | セクション内に含まれる画像やメディアへのリンク |
| 📖 参考文献 | セクションで引用されている参考文献リスト |
2. Wikipedia検索結果ページの抽出
Wikipediaスクレイパーは、検索結果ページからもデータを抽出できます。複数のトピックを一度に収集したい場合や、検索トレンドの分析、関連テーマのデータ収集に便利です。
手順:
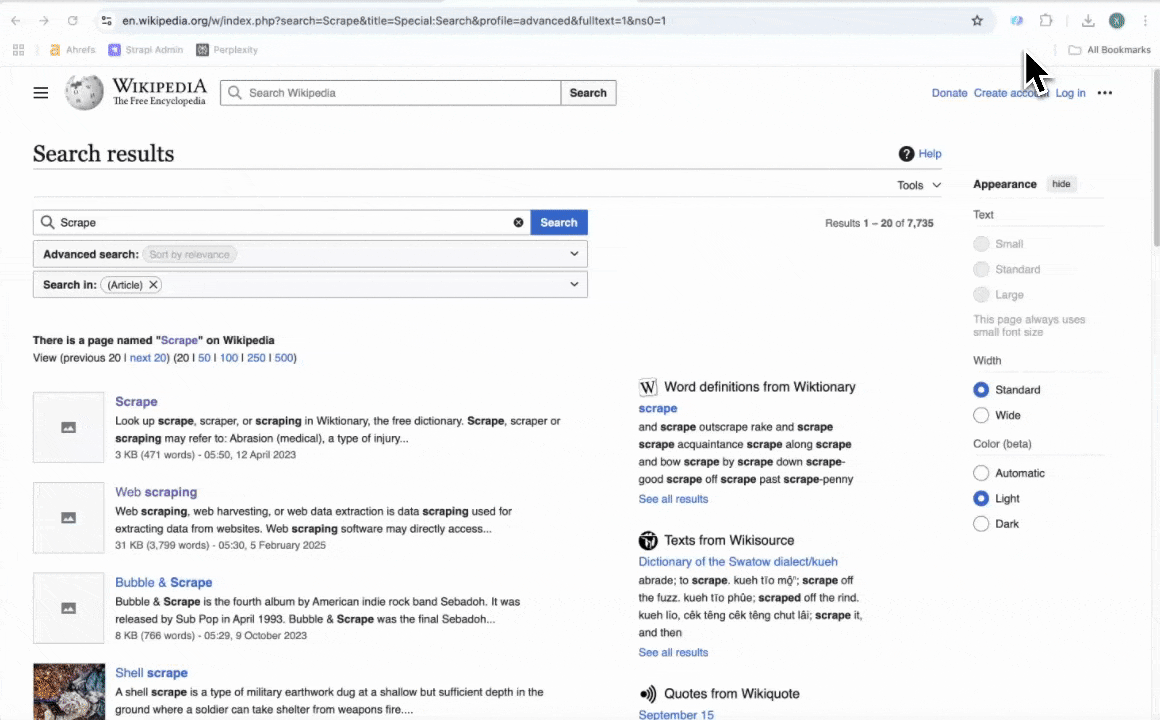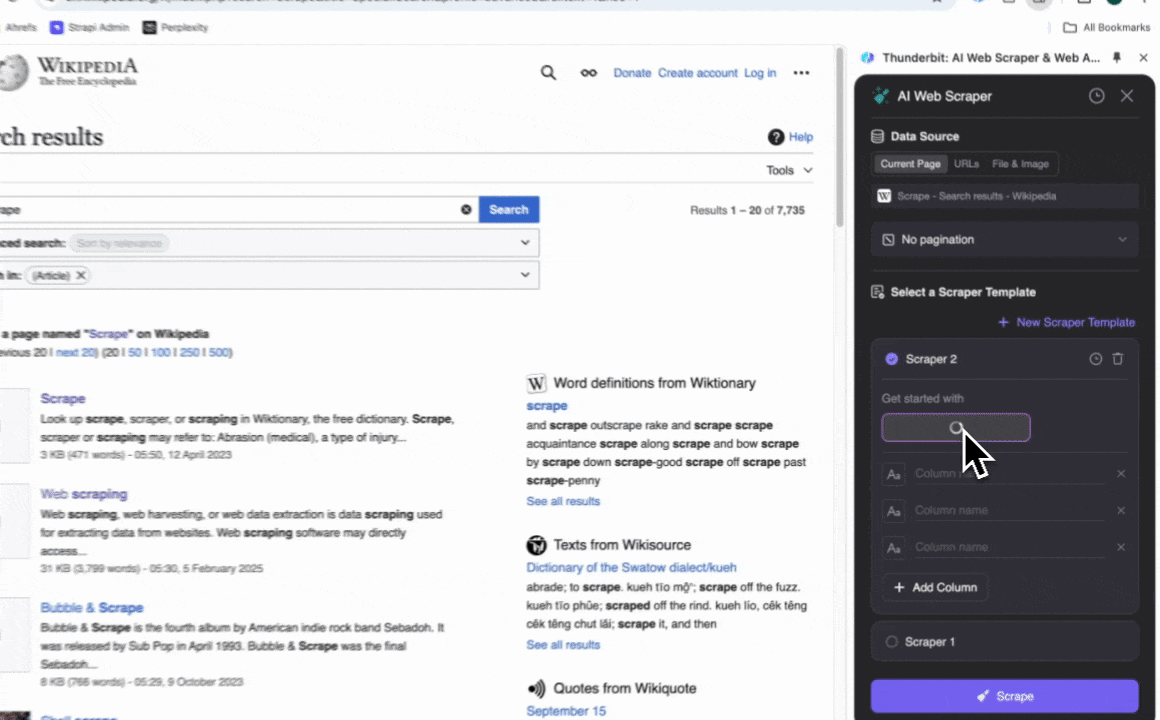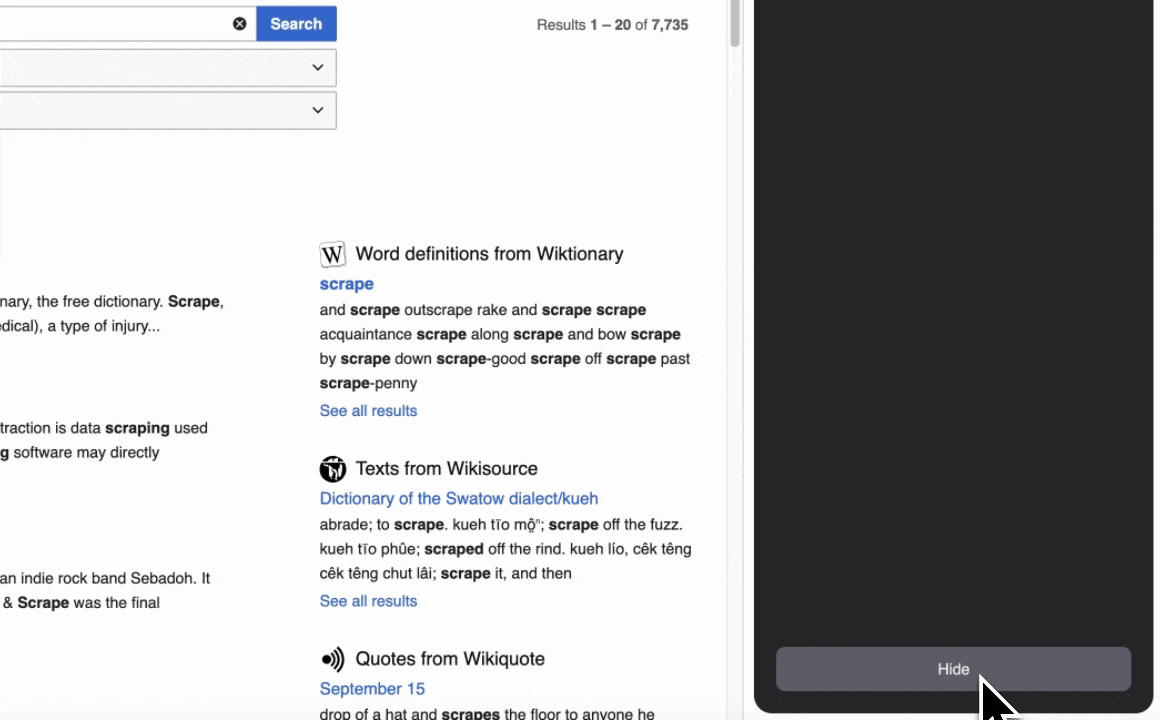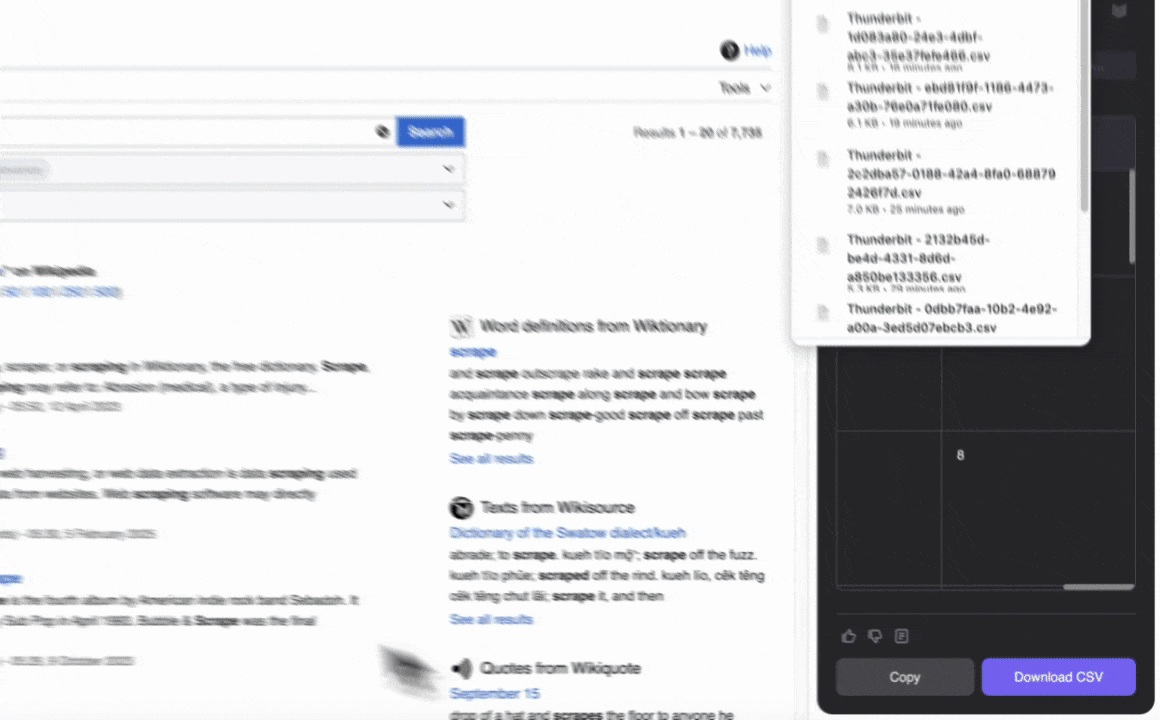
- をインストールし、アカウント登録を行います。
- にアクセスします。
- AIカラム提案をクリックすると、「結果タイトル」「結果URL」などのカラム名が自動で提案されます。
- スクレイプをクリックしてデータを抽出し、構造化フォーマットでダウンロードします。
カラム例
| カラム | 説明 |
|---|---|
| 📝 結果タイトル | 検索結果のタイトル |
| 🌐 結果URL | 検索結果への直接リンク |
| 🖋️ 結果の説明 | 検索結果の簡単な説明 |
| 📅 最終更新日 | ページが最後に更新された日付 |
| 📏 ページサイズ(単語数) | 検索結果ページの単語数 |
🤔 Wikipediaスクレイパーを使うメリット
Wikipediaのデータを自動で取得することで、さまざまな分野のプロフェッショナルが効率的に作業できます:
- 研究者:学術調査や市場調査のためのデータ収集・整理がスピーディーに。
- 学生:レポートや課題用に要約や参考文献を簡単に抽出。
- コンテンツ制作者:トレンド分析や記事・動画制作のための情報収集に。
- データアナリスト:分析や可視化に使える構造化データを手軽に取得。
Wikipediaスクレイパーを活用すれば、手作業でのコピペ作業に時間を取られることなく、データ分析や活用に集中できます。
🛠️ Wikipediaスクレイパー Chrome拡張機能の使い方
- Thunderbit Chrome拡張機能をインストール:から拡張機能をダウンロードし、アカウント登録を行います。
- Wikipediaページにアクセス:抽出したいWikipediaエントリーや検索結果ページを開きます。
- AIスクレイパーを起動:AIカラム提案をクリックしてカラム名を自動生成、またはカスタマイズも可能です。
- スクレイプを実行:スクレイプをクリックしてデータを抽出し、構造化フォーマットでダウンロードします。
💰 Thunderbit Wikipediaスクレイパーの料金プラン
Thunderbitはクレジット制を採用しており、1クレジット=1行のデータ抽出です。無料トライアルもあり、利用頻度に応じて柔軟なプランを選べます。
料金プラン例:
| プラン | 月額料金 | 年額料金(月換算) | 年額合計 | 月間クレジット | 年間クレジット |
|---|---|---|---|---|---|
| 無料 | 無料 | 無料 | 無料 | 6ページ | N/A |
| スターター | $15 | $9 | $108 | 500 | 5,000 |
| Pro 1 | $38 | $16.5 | $199 | 3,000 | 30,000 |
| Pro 2 | $75 | $33.8 | $406 | 6,000 | 60,000 |
| Pro 3 | $125 | $68.4 | $821 | 10,000 | 120,000 |
| Pro 4 | $249 | $137.5 | $1,650 | 20,000 | 240,000 |
無料プランの特典:
- 無料プランで月6ページまで利用可能
- 無料トライアルで10ページまでお試し可能。スクレイパーの機能を気軽に体験できます。
❓ よくある質問
-
AI搭載Wikipediaスクレイパーとは?
AI搭載Wikipediaスクレイパーは、Wikipediaのエントリーや検索結果ページから構造化データを抽出するための専用ツールです。ThunderbitのAI搭載Chrome拡張機能を活用し、専門知識がなくても簡単に情報収集ができます。
-
Thunderbitとは?
Thunderbitは、AI技術を活用してウェブスクレイピングやデータ抽出、自動化を簡単にするChrome拡張機能です。ウェブサイトからのデータ取得、フォーム自動入力、コンテンツ要約など、さまざまな業務を効率化します。
-
無料トライアルで何ページまで抽出できますか?
Thunderbitの無料トライアルでは、最大10ページのWikipediaデータを無料で抽出できます。ツールの機能を十分に試してから有料プランへの切り替えを検討できます。
-
抽出するカラムやデータ項目はカスタマイズできますか?
はい、Thunderbitは柔軟なカスタマイズ機能を備えており、抽出したいデータ項目を自由に指定できます。セクションタイトルやURL、要約、参考文献など、用途に合わせて設定可能です。
-
スクレイパーの利用頻度に制限はありますか?
利用頻度はご契約プランと保有クレジット数によって異なります。上位プランほど多くのクレジットが付与され、大規模なデータ抽出や頻繁な利用が可能です。
-
クレジットがなくなった場合はどうなりますか?
クレジットが不足した場合は、追加購入や上位プランへのアップグレードが簡単に行えます。必要なときにいつでも機能を継続利用できます。
-
Wikipediaのデータ抽出は合法ですか?
Wikipediaの公開データを抽出すること自体は、関連法令やWikipediaの利用規約を遵守していれば一般的に問題ありません。データの利用は責任を持って行い、各種規定に従ってください。
-
Wikipediaから画像やメディアも抽出できますか?
はい、Wikipediaスクレイパーはエントリー内の画像やメディアへのリンクも抽出可能です。ビジュアルコンテンツが必要な研究者やコンテンツ制作者にも便利です。
📚 詳しく知りたい方へ
Thunderbitの詳細や機能についてはやでチュートリアルや活用法をご覧いただけます。