L’Extracteur Wikipedia alimenté par l’IA de Thunderbit est un outil performant conçu pour extraire des données structurées à partir des articles Wikipedia et des pages de résultats de recherche. Avec la , transformez en quelques clics le contenu non structuré de Wikipedia en jeux de données organisés. Que vous soyez chercheur, étudiant ou analyste, cet outil simplifie la collecte d’informations issues de l’une des plus grandes encyclopédies en ligne.

📖 Que pouvez-vous extraire avec l’Extracteur Wikipedia ?
1. Extraire le contenu d’un article Wikipedia
L’Extracteur Wikipedia vous permet de récupérer des informations détaillées depuis n’importe quel article : titres de sections, liens directs, résumés, médias et références. Parfait pour les professionnels et chercheurs qui souhaitent analyser ou archiver le contenu de Wikipedia.
Étapes :
- Installez la et créez un compte.
- Rendez-vous sur la .
- Cliquez sur AI Suggest Columns pour obtenir des suggestions de colonnes comme Titre de section, Résumé, etc.
- Cliquez sur Scrape pour extraire les données et les télécharger dans un format structuré.

Noms des colonnes
| Colonne | Description |
|---|---|
| 📚 Titre de section | Le titre de chaque section de l’article Wikipedia. |
| 🌐 URL de la section | Le lien direct vers la section spécifique de la page. |
| 📝 Résumé du contenu | Un résumé concis du contenu de chaque section. |
| 🖼️ Médias/Images | Liens vers les médias ou images présents dans la section. |
| 📖 Références | Liste des références citées dans la section. |
2. Extraire les résultats de recherche Wikipedia
L’Extracteur Wikipedia permet aussi de récupérer les données des pages de résultats de recherche, facilitant la collecte d’informations sur plusieurs sujets en une seule fois. Idéal pour les chercheurs ou créateurs de contenu qui souhaitent analyser des tendances ou compiler des données sur des thématiques liées.
Étapes :
- Installez la et créez un compte.
- Accédez à la .
- Cliquez sur AI Suggest Columns pour obtenir des suggestions de colonnes comme Titre du résultat, URL du résultat, etc.
- Cliquez sur Scrape pour extraire les données et les télécharger dans un format structuré.
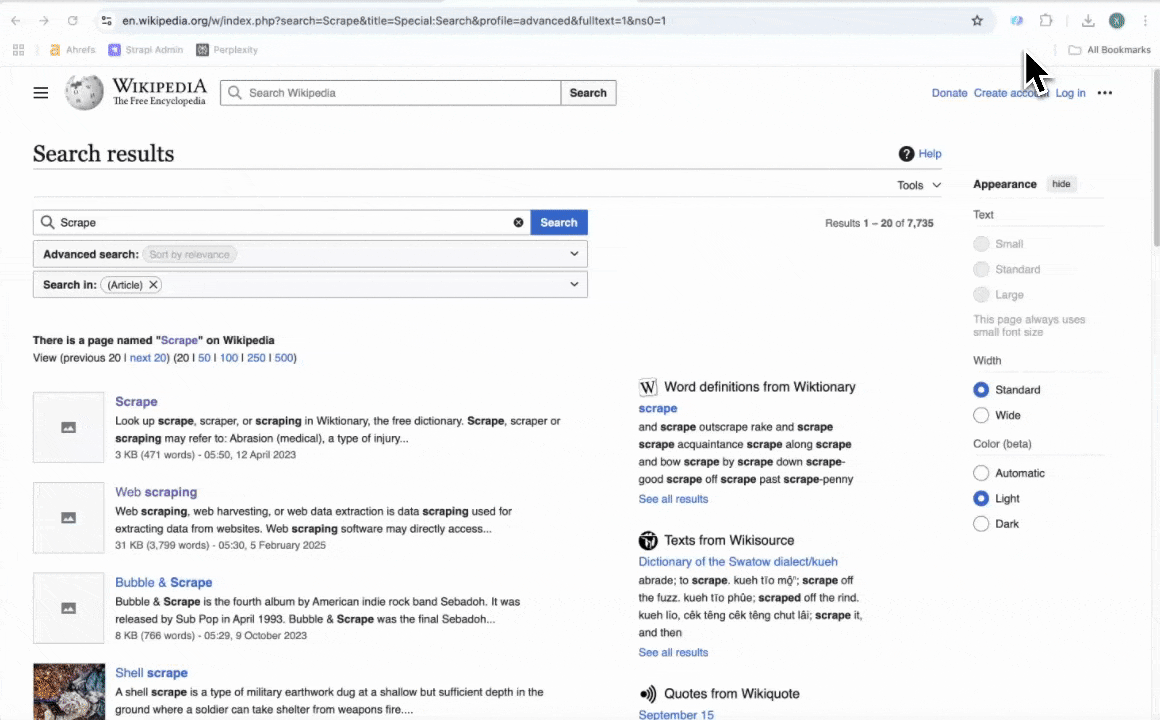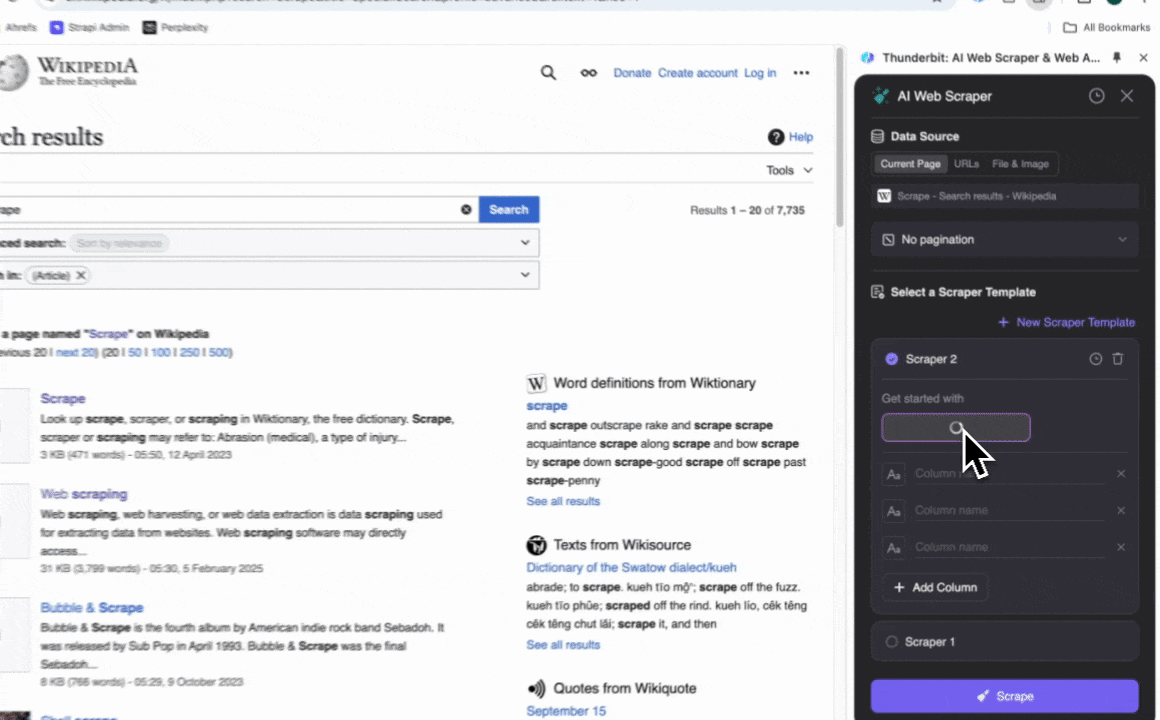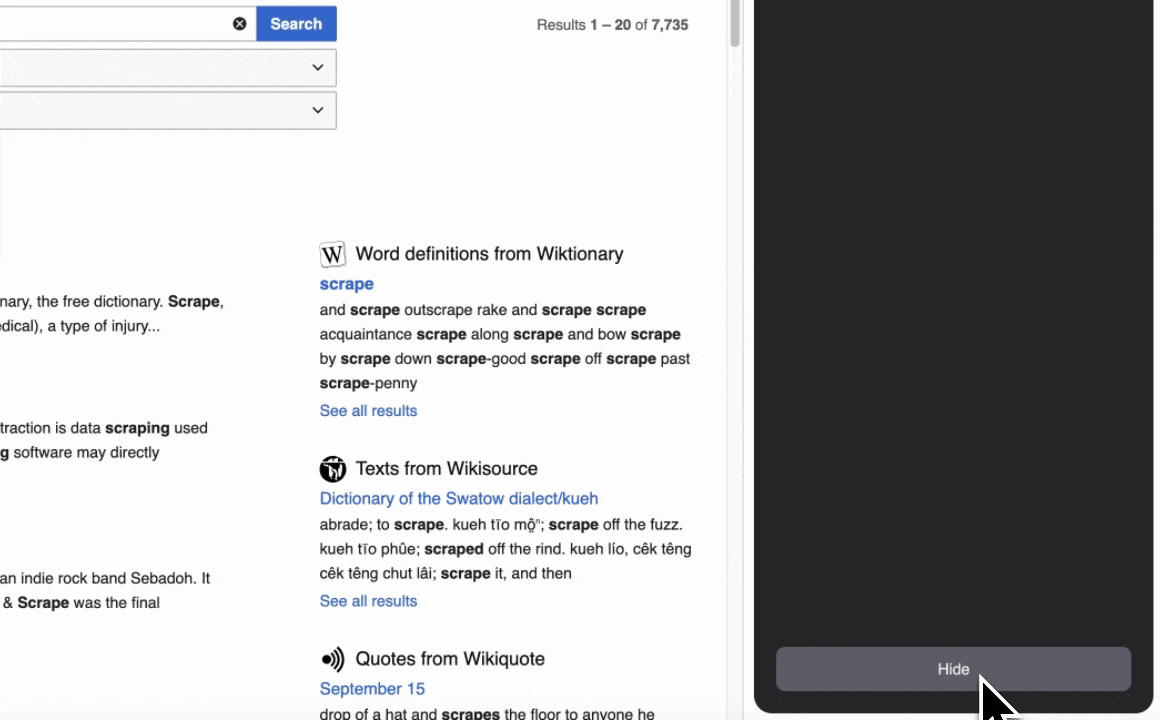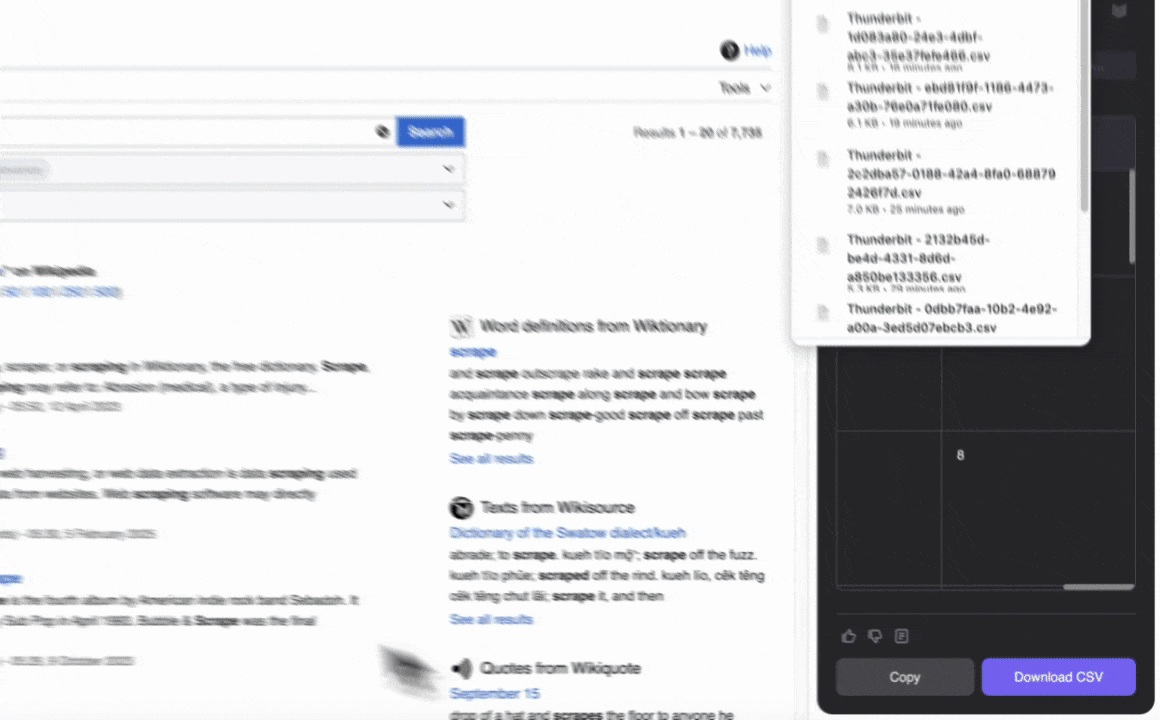
Noms des colonnes
| Colonne | Description |
|---|---|
| 📝 Titre du résultat | Le titre du résultat de recherche. |
| 🌐 URL du résultat | Le lien direct vers le résultat. |
| 🖋️ Description du résultat | Un court descriptif du résultat de recherche. |
| 📅 Date de dernière modification | La date de la dernière mise à jour de la page. |
| 📏 Taille du résultat (mots) | Nombre de mots de la page de résultat. |
🤔 Pourquoi utiliser l’Extracteur Wikipedia ?
Extraire des données de Wikipedia permet de gagner du temps et d’obtenir des informations précieuses pour de nombreux profils :
- Chercheurs : Collectez et organisez rapidement des données pour vos études ou analyses de marché.
- Étudiants : Récupérez des résumés et références pour vos travaux ou exposés.
- Créateurs de contenu : Analysez les tendances et compilez des informations pour vos articles ou vidéos.
- Analystes de données : Rassemblez des données structurées pour l’analyse et la visualisation.
Avec l’Extracteur Wikipedia, concentrez-vous sur l’analyse des données plutôt que sur la copie manuelle fastidieuse.
🛠️ Comment utiliser l’extension Chrome Extracteur Wikipedia
- Installez l’extension Chrome Thunderbit : Téléchargez l’extension depuis le et créez votre compte.
- Accédez à la page Wikipedia souhaitée : Rendez-vous sur l’article ou la page de résultats à extraire.
- Activez l’extracteur IA : Cliquez sur AI Suggest Columns pour générer ou personnaliser les colonnes selon vos besoins.
- Lancez l’extraction : Cliquez sur Scrape pour extraire et télécharger les données dans un format structuré.
💰 Tarifs de l’Extracteur Wikipedia Thunderbit
Thunderbit fonctionne sur un système de crédits : 1 crédit = 1 ligne extraite. L’outil est gratuit à l’essai, et plusieurs formules s’adaptent à tous les usages, occasionnels ou intensifs.
Formules :
| Formule | Prix mensuel | Prix annuel | Coût total annuel | Crédits/mois | Crédits/an |
|---|---|---|---|---|---|
| Gratuit | Gratuit | Gratuit | Gratuit | 6 pages | N/A |
| Starter | 15 $ | 9 $ | 108 $ | 500 | 5 000 |
| Pro 1 | 38 $ | 16,5 $ | 199 $ | 3 000 | 30 000 |
| Pro 2 | 75 $ | 33,8 $ | 406 $ | 6 000 | 60 000 |
| Pro 3 | 125 $ | 68,4 $ | 821 $ | 10 000 | 120 000 |
| Pro 4 | 249 $ | 137,5 $ | 1 650 $ | 20 000 | 240 000 |
Fonctionnalités gratuites :
- 6 pages par mois avec la formule gratuite.
- 10 pages offertes avec l’essai gratuit, idéal pour découvrir toutes les fonctionnalités de l’extracteur.
❓ FAQ
-
Qu’est-ce que l’Extracteur Wikipedia alimenté par l’IA ?
Il s’agit d’un outil spécialisé pour extraire des données structurées à partir des articles et résultats de recherche Wikipedia. Grâce à l’extension Chrome IA de Thunderbit, la collecte d’informations devient simple et accessible, même sans compétences techniques.
-
Qu’est-ce que Thunderbit ?
Thunderbit est une extension Chrome polyvalente qui utilise l’intelligence artificielle pour simplifier l’extraction de données, le web scraping et l’automatisation. Elle permet de collecter des données sur des sites web, de remplir automatiquement des formulaires et de résumer du contenu, ce qui en fait un outil incontournable pour de nombreux professionnels.
-
Combien de pages Wikipedia puis-je extraire avec l’essai gratuit ?
Avec l’essai gratuit de Thunderbit, vous pouvez extraire jusqu’à 10 pages Wikipedia sans frais. Cela vous permet de tester l’outil et de vérifier s’il répond à vos besoins avant de passer à une formule payante.
-
Puis-je personnaliser les colonnes et champs à extraire ?
Oui, Thunderbit offre de nombreuses options de personnalisation pour choisir précisément les champs à extraire : titres de section, liens, résumés, références, etc. L’outil s’adapte à vos besoins.
-
À quelle fréquence puis-je utiliser l’extracteur ?
La fréquence d’utilisation dépend de votre formule d’abonnement et du nombre de crédits disponibles sur votre compte. Les formules supérieures incluent plus de crédits pour des extractions plus fréquentes ou volumineuses.
-
Que se passe-t-il si je n’ai plus de crédits ?
Si vous épuisez vos crédits, vous pouvez en acheter à la demande ou passer à une formule supérieure pour continuer à utiliser l’extracteur sans interruption.
-
Est-il légal d’extraire des données de Wikipedia ?
L’extraction de données accessibles publiquement sur Wikipedia est généralement autorisée, à condition de respecter la législation en vigueur et les conditions d’utilisation de Wikipedia. Il est important d’utiliser les données de manière responsable et conforme à la réglementation.
-
Puis-je extraire les médias et images de Wikipedia ?
Oui, l’Extracteur Wikipedia permet de récupérer les liens vers les médias et images présents dans les articles. Cette fonctionnalité est particulièrement utile pour les chercheurs et créateurs de contenu ayant besoin de ressources visuelles.
📚 En savoir plus
Pour découvrir toutes les fonctionnalités de Thunderbit, rendez-vous sur le ou consultez la pour des tutoriels et astuces.